Operating a single-node Mongo cluster is a relatively easy task. However, such a setup always comes with some serious downsides. Specifically, we’ll have a hard time providing high availability and good performance when the database is under an increased load.
One way to boost the read performance of Mongo is to introduce replicas. In such case, all writes go through a primary. Reads, on the other hand, are served by one of the replicas, provided that the read preference is configured accordingly.
For example, when building a data syncing application, we download the data from a source and write it to the primary. If we try to retrieve the same recently stored data from a replica for it to be synced to a destination, then we may see stale data, as the replication process in Mongo is asynchronous. This, in turn, means that we sync out-of-date data to the desired destination and provide the customers with a solution they’re not happy with.
That’s exactly where causal consistency can save us.
In this article, we’re going to look into causal consistency, understand what is it, and how can it solve consistency issues in Mongo.
1. What is Causal Consistency?
When talking about causal consistency, we consider consistency in the context of the CAP theorem. The CAP theorem states that when managing a distributed datastore, we need to balance between availability and consistency.
Availability is an attribute which indicates the capability of a database to return a timely response. Consistency is an attribute indicating how predictable reads are from a distributed datastore.
For example, the two sides of the consistency axis are strict consistency and eventual consistency. With strict consistency we’re guaranteed to read the latest data written, no matter from which replica we read the data from. In addition, every reader observes the same order of writes. On the contrary, eventual consistency means that we may read out-of-date data and we can’t make any assumptions about the order of writes.
A strictly consistent database is much less available than an eventually consistent one.
Causal consistency is the middle ground. It is a type of consistency that ensures the order of causally-related operations across multiple database sessions. Causal consistency doesn’t care about the order of operations that are not causally related.
For example, in a chat application, if user A sends a message and user B replies to it, then we would expect first the message from A to appear before the message of B. However, reading the data from an eventually consistent replica doesn’t guarantee that we will see the messages in the correct order. This kind of anomaly is a violation of causal consistency.
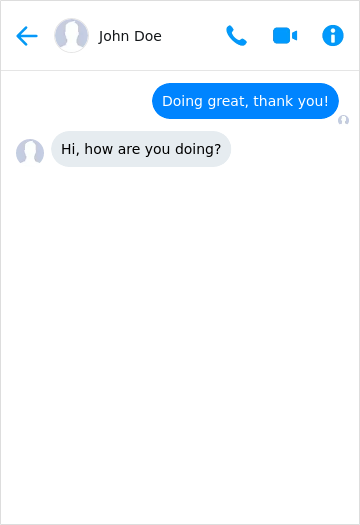
Figure 1.1. An example of causal consistency not guaranteed
Theoretically speaking causal consistency is made up of the following guarantees:
- read-your-writes consistency
- monotonic-reads consistency
- monotonic-writes consistency
- writes-follows-reads consistency
Before we move on to the practical implementation, let’s see in detail the four guarantees and what they mean exactly.
1.1. Read-Your-Writes Consistency
Read-your-writes guarantees that whenever we write something to the database, we should be able to read it ourselves.
Figure 1.2. shows a violation of read-your-writes consistency. The user writes a message to the primary. When they refresh the page, then they don’t see the message at all because the read was directed to a replica that had stale data.
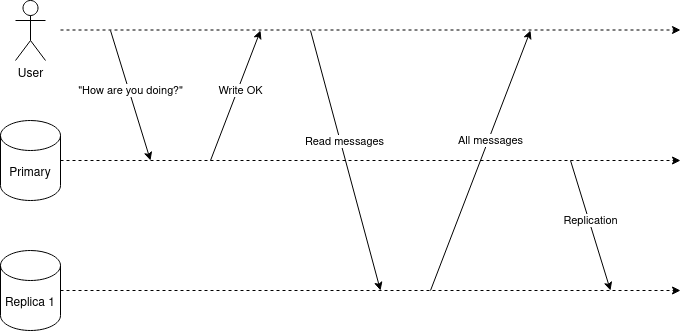
Figure 1.2. A violation of read-your-writes consistency
1.2. Monotonic-Reads Consistency
Monotonic-reads is a guarantee that we don’t see flickering values.
For example, if we send a message, then we should see it, no matter how many times we fetch the data. If we see the message for the first time, but don’t see it the second time, then the application doesn’t provide monotonic-reads consistency.
Figure 1.3. indicates a violation of monotonic-reads consistency. During the first read, the client reads messages from replica 1 that already has the latest state. The next read for the same data hits replica 2 which has not yet received the latest state.
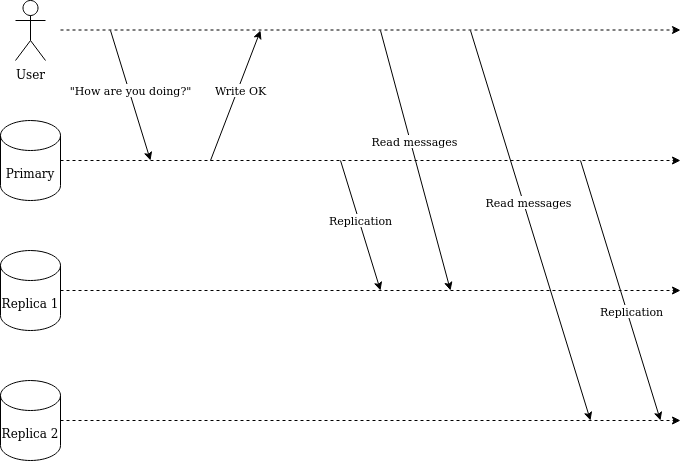
Figure 1.3. A violation of monotonic-reads consistency
1.3. Monotonic-Writes Consistency
Monotonic-writes consistency ensures that if we execute write 1 and then write 2, then all the database instances in a cluster execute the writes in the same order.
A violation of monotonic-writes consistency would happen if a user first tried to write a message “How are you doing?” to the primary. If the primary crashes before the replication process has successfully been completed, then one of the replicas would step up as the new primary.
As the first message was not replicated to replica 1, which became the new primary, then the first write is lost. The clients won’t observe that “How are you doing?” was written before “I hope you’re doing good”, and monotonic-writes consistency was broken.
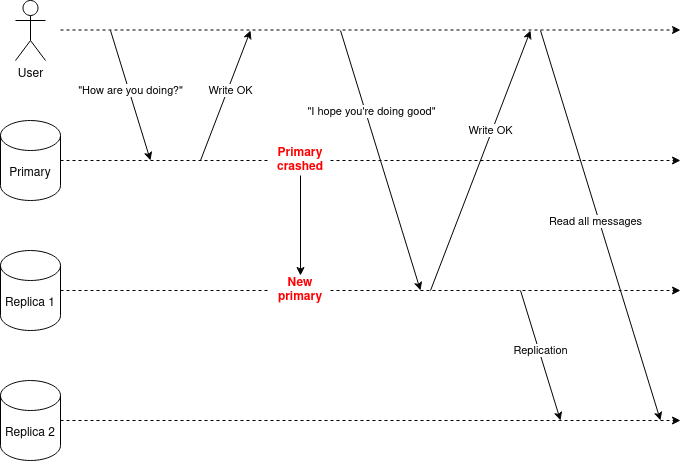
Figure 1.4. Monotonic-writes not preserved after the initial primary crashed
1.4. Writes-Follow-Reads Consistency
Writes-follow-reads-consistency guarantees that if we read data from the database that’s a result of write 1 and then perform write 2, then W2 should be visible after W1.
In Figure 1.5, the first write and the first read both hit the primary. If the initial primary crashes after read 1, then replica 1 is assigned as the new primary.
Provided that there hasn’t been any replication process between primary and replica 1 before the failover, then the first write will be lost. Hence, the read operation after the W1 won’t be in the new primary during the second write.
Figure 1.5. Writes-follows-read consistency is not guaranteed after the primary crashed
2. Causal Consistency in Mongo
In this section, we’re going to look at how to achieve causal consistency in Mongo.
2.1. Read and Write Concerns
To achieve true causal consistency in Mongo, we first need to set read and write concerns.
Write concern helps to describe how many nodes in the cluster need to acknowledge the writes. The default value is majority (starting from Mongo 5.0), meaning that the majority of the nodes in a cluster need to accept the write for it to be considered successful. However, write concern can also be set to 1, meaning that only the primary needs to acknowledge the write.
In general, we should avoid changing the default value of write concern from majority to 1 without serious consideration. majority ensures us that if the primary of the cluster crashes, then no writes are lost as they were replicated to the majority of the nodes when the write was successful.
Read concern allows for controlling the consistency and isolation levels. By default, the value is set to local, meaning that the data returned by a read query needs to be acknowledged by a single instance specified by the read preference. An instance can be either the primary or one or more replicas. However, there’s no guarantee that the read result we see won’t be rolled back if the write concern is set to 1.
Setting read concern to majority means that the majority of nodes in the cluster need to have acknowledged the data.
An important thing to note about the read concern majority. For example, if there are 5 nodes in the cluster (1 primary and 4 replicas), then the read is not sent to multiple nodes. Quite the opposite, the read is sent to just a single node specified by the read preference option. The node that replies to the query has its knowledge of the latest majority committed write. Hence, the read concern majority only guarantees us durability. By ensuring durability, we can be sure that the data we read will never be rolled back. However, it won’t guarantee us read-your-writes consistency because the instance we’re reading the data from may not have the latest majority-committed write available.
2.1.1 Setting Read and Write Concerns
Setting both the read and write concerns is fairly trivial.
For example, a standard write operation looks like this:
To set write concern, we need to pass an additional option to the method.
The same goes for setting the read concern.
We just need to pass readConcern option to the read query.
2.2. Cluster Time
Besides read and write concerns, we also need to take advantage of Mongo’s cluster time. The goal is to ensure that we never fall back in time when executing queries.
With every operation that the client sends to Mongo, it needs to attach a timestamp. For example, if the client tries to read a row from a replica, then by passing a timestamp to the read query, the client states that the replica should return only after it is guaranteed to have records later than the specified timestamp.
To keep the cluster time up-to-date within the cluster, every node sends the latest known cluster time whenever talking to another node in the cluster.
Figure 2.1. indicates the concept. When reading the messages, the user specifies that he wants to read them after timestamp T1. If replica 1 has not yet received the updates and the timestamp of the instance is smaller than T1, then the read blocks until the timestamp is equal to or larger than T1. When the timestamp is T1, then the user can be sure that he sees the data he wrote.
Figure 2.1. Reading from a replica with a cluster time
2.1.1 Using Cluster Time in Node.js
The code below connects to a Mongo replica set, writes a record to a collection, and then immediately tries to retrieve it.
Provided that the replication lag between the master and the replica is sufficient, then foundDocument will be null. This is an issue when trying to achieve causal consistency.
To fix the issues, we need to use Mongo ClientSessions.
We first create a new client session with causalConsistency set to true. The session object has a property clusterTime that gets updated every time we execute either read or write operation.
The same session object needs to be passed to every interaction we’re doing with Mongo within a single causally consistent session.
3. Conclusion
In this article, we took a look into causal consistency.
Causal consistency ensures that all operations within a causally-related session appear in the order they were written initially. It’s not as strict as strong consistency, but stronger than eventual consistency.
To achieve causal consistency in Mongo, you need to tune two different parameters: read/write consistency and cluster time. By setting read and write consistency to majority we can guarantee that the reads and writes are durable and will never be rolled back. Cluster time, on the other hand, helps us to guarantee that we never fall back in time.