1. Introduction
Whenever we want to display large amounts of data to a user, paginating the database response should be our first option.
Implementing pagination itself might be easy, but creating a performant solution is a bit more complicated and involves several tradeoffs.
In this article, we’re going to look into different pagination options in MongoDB and see their main benefits and downsides.
2. Pagination with Skip and Limit
The most common approach to pagination is to use Mongo’s skip and limit. It is really straightforward and easy to get started, but there is a big issue: the larger the skip value, the slower the requests get.
Let’s imagine we are serving the requests using the following controller:
const db = require('../../db');
module.exports = async (req, res) => {
const { limit, offset } = req.query;
const units = await db.collection('units')
.find({})
.skip(Number(offset))
.limit(Number(limit))
.toArray();
const documentsCount = await db.collection('units').countDocuments({});
res.send({
data: [],
pagination: {
hasNextPage: documentsCount >= Number(offset) + Number(limit),
nextOffset: Number(offset) + Number(limit)
}
})
}Here’s a graph which shows the request duration for a database with over 5,000,000 records:
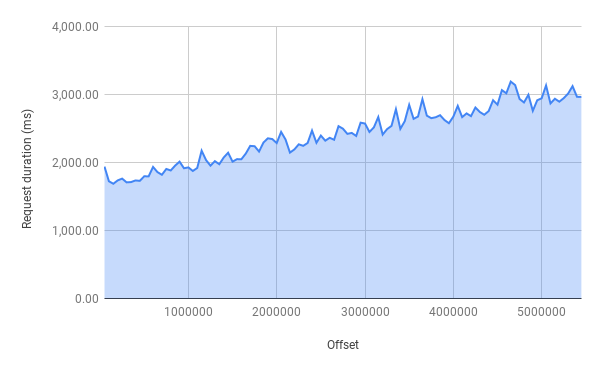
As we can see, the larger the offset, the slower the request gets. For example, compared to offset 0, offsets of 5,000,000 takes more than 50% longer - this graph looks very much like O(n).
Where is the exact issue there?
In order to find the root cause of the apparent slowdown, we can use the Mongo explain to understand the exact logic of the query. Let’s execute the following command in the Mongo shell:
db.units.find({}).limit(20).skip(1000000).explain("executionStats")We should see a response like this:
{
"executionStats":{
"executionSuccess":true,
"nReturned":20,
"executionTimeMillis":792,
"totalKeysExamined":0,
"totalDocsExamined":1000020,
"executionStages":{
"stage":"LIMIT",
"nReturned":20,
"executionTimeMillisEstimate":70,
"works":1000022,
"advanced":20,
"needTime":1000001,
"needYield":0,
"saveState":1000,
"restoreState":1000,
"isEOF":1,
"limitAmount":20,
"inputStage":{
"stage":"SKIP",
"nReturned":20,
"executionTimeMillisEstimate":65,
"works":1000021,
"advanced":20,
"needTime":1000001,
"needYield":0,
"saveState":1000,
"restoreState":1000,
"isEOF":0,
"skipAmount":0,
"inputStage":{
"stage":"COLLSCAN",
"nReturned":1000020,
"executionTimeMillisEstimate":57,
"works":1000021,
"advanced":1000020,
"needTime":1,
"needYield":0,
"saveState":1000,
"restoreState":1000,
"isEOF":0,
"direction":"forward",
"docsExamined":1000020
}
}
}
}
}Digging further, we need to look the at key executionStats. Examining the root-level keys totalDocsExamined and nReturned, we can see that in order to serve the skip and limit query with offset 1,000,000, the database needs to scan 1,000,020 records while just returning 20 records. What a waste of the resources!
In an ideal world, whenever we scan a record, we would like to also return it (i.e. the relation between totalDocsExamined and nReturned should be 1:1). Keeping this in mind helps us to write very efficient database queries.
3. Pagination with Cursor
Pagination with a cursor is one possible alternative to the skip and limit approach.
Instead of returning the numerical offset in the response data, the response should contain a reference to the next item in the list. When making a query to fetch the next page of the data, we have to pass the returned reference back to the query instead of the numerical offset.
If the referenced field is properly indexed, we should see a constant-time performance. Let’s imagine that we have the following controller:
const { ObjectID } = require('mongodb')
const db = require('../../db');
module.exports = async (req, res) => {
const { limit, offset } = req.query;
const query = offset ? { _id: { $gt: ObjectID(offset) } } : {};
const units = await db.collection('units')
.find(query)
.limit(Number(limit))
.toArray();
res.send({
data: units,
pagination: {
nextOffset: units[units.length - 1]._id
}
})
}As we can see, instead of returning the offset as a number, we return the ID of the last item in the array which serves as the indicator telling us where were we left off. The next time a client passes an offset to the request, we query it using $gt.
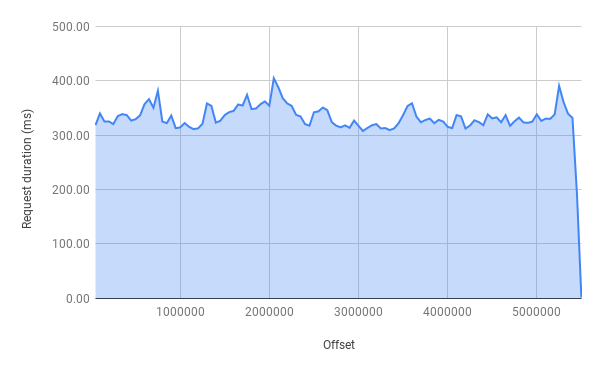
Looking at the graph above, we can see that no matter how far are we with traversing the list of records, the performance stays roughly the same - O(1).
Executing explain reveals that this time totalDocsExamined is exactly equal to nReturned.
db.units
.find({_id: {$gt: ObjectId('600f46ae04d46f5b82acbab0')}})
.limit(50000)
.explain('executionStats'){
"executionStats":{
"executionSuccess":true,
"nReturned":50000,
"executionTimeMillis":39,
"totalKeysExamined":50000,
"totalDocsExamined":50000,
"executionStages":{
"stage":"LIMIT",
"nReturned":50000,
"executionTimeMillisEstimate":2,
"works":50001,
"advanced":50000,
"needTime":0,
"needYield":0,
"saveState":50,
"restoreState":50,
"isEOF":1,
"limitAmount":50000,
"inputStage":{
"stage":"FETCH",
"nReturned":50000,
"executionTimeMillisEstimate":2,
"works":50000,
"advanced":50000,
"needTime":0,
"needYield":0,
"saveState":50,
"restoreState":50,
"isEOF":0,
"docsExamined":50000,
"alreadyHasObj":0,
"inputStage":{
"stage":"IXSCAN",
"nReturned":50000,
"executionTimeMillisEstimate":1,
"works":50000,
"advanced":50000,
"needTime":0,
"needYield":0,
"saveState":50,
"restoreState":50,
"isEOF":0,
"keyPattern":{
"_id":1
},
"indexName":"_id_",
"isMultiKey":false,
"multiKeyPaths":{
"_id":[
]
},
"isUnique":true,
"isSparse":false,
"isPartial":false,
"indexVersion":2,
"direction":"forward",
"indexBounds":{
"_id":[
"(ObjectId(\\'600f46ae04d46f5b82acbab0\\'), ObjectId(\\'ffffffffffffffffffffffff\\')]"
]
},
"keysExamined":50000,
"seeks":1,
"dupsTested":0,
"dupsDropped":0
}
}
}
}
}As we’re using the comparison operator when requesting records, we always have to ensure that the offset value is orderable and unique.
For example, it’s perfectly fine to use either an integer, Mongo ID or a Version 1 UUID which contains a timestamp. However, we can’t use a value which is not sortable as an offset as we have no way to determine the exact orders of the records.
On the other hand, there’s a major drawback to the cursor-based approach. Namely, we can’t jump to a specific page in the list of contacts as we do with the skip and limit.
3. Bucket-based Pagination
Bucket-based pagination offers a solution to the previous problem: on one hand, it’s significantly faster than the skip-based approach, but it allows going to a specific page.
Let’s imagine that all of the records in units collection are in the following form:
{
"_id":"6014950f48addb3be286c500",
"Area":"A100100",
"year":"2000",
"geo_count":"96",
"ec_count":"130",
"user":"6014962f3200153be21c7834"
}The bucket-based approach offers an alternative by bucketing multiple records into a single bucket:
{
"_id": "6014a865562a6ea746d3c4cb",
"user": "6014962f3200153be21c7834",
"count": 5000,
"units": [
{
"_id": "6014950f48addb3be286d718",
"area": "A300900",
"year": "2000",
"geo_count": "6",
"ec_count": "12"
},
{
"_id": "6014950f48addb3be286d71d",
"area": "A301600",
"year": "2000",
"geo_count": "3",
"ec_count": "6"
},
{
"_id": "6014950f48addb3be286d722",
"area": "A302400",
"year": "2000",
"geo_count": "3",
"ec_count": "3"
}
]
}For example, if we decide to have 5,000 elements in a single bucket, then instead of having 5,000,000 records in the database, we should end up with just a 1,000 records.
The controller for traversing the records looks like this:
const db = require('../../db');
module.exports = async (req, res) => {
const { page = 0 } = req.query;
const units = await db.collection('grouped_units')
.find({})
.skip(Number(page))
.limit(1)
.toArray();
const documentsCount = await db.collection('grouped_units')
.countDocuments({});
res.send({
data: units.units,
pagination: {
hasNextPage: documentsCount >= Number(page),
nextPage: Number(page) + 1
}
})
}Note that once again, we’re using skip, but this time it’s way more efficient. Even if we are at the end of the records, we just need to scan a maximum of 1,000 records compared to the situation in Paragraph 2, where we had to scan over almost 5,000,000 elements.
Looking at the request duration graph, we can see that it looks like a linear one, meaning that no matter which page we’re at, the complexity of this approach should stay roughly the same.
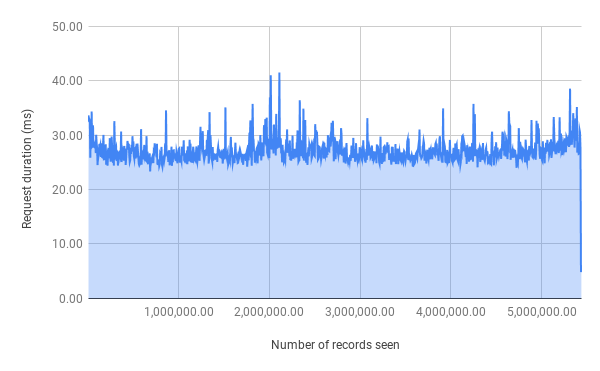
Unfortunately there are no silver bullets in this game and this method has its’ downsides. The most important one probably is that, it’s a bit more complex to insert, delete or update an individual record inside the bucket.
For example, in order to insert a record to a bucket, we have to execute this query:
db.collection('units').updateOne({
user: user.id,
"count": {
$lt: 5000
}
}, {
$push: {
units: unit
},
$inc: {
"count": 1
},
$setOnInsert: {
user: user.id
}
}, {
upsert: true
})The query looks up a single record in the units collection which has less items than the threshold of 5,000 and then push the item there.
Because the maximum document size in Mongo can be 16MB, we have to pay attention that we don’t exceed that limit. Hence, we should be careful when storing large documents inside the buckets.
4. Conclusion
Returning a paginated response is a required for almost every client-facing application.
Even though paginating response data with Mongo’s skip and limit is relatively straightforward, skip causes the queries to be of complexity of O(n).
To create a performant contasnt-time pagination solution, we need to look either into using the cursor-based approach or start using buckets for storing the data.