Kafka has become one of the most prominent players in the event streaming space. Both small companies and large corporations have found Kafka to be extremely beneficial for achieving their business goals.
Kafka is a tool with a lot of unknown features that can be put to good use. One such feature is log compaction.
This article takes a deep dive into log compaction and introduces its theoretical and practical sides.
The article expects that the reader is familiar with Kafka basics such as partitions and topics.
1. What is Log Compaction?
It’s common to use Kafka as a commit log. That is, there’s one log file per partition. Every time a record is dispatched to Kafka, the entry is appended to the end of the log of a certain partition. The exact partition can be, for example, determined randomly or by the ID of the message.
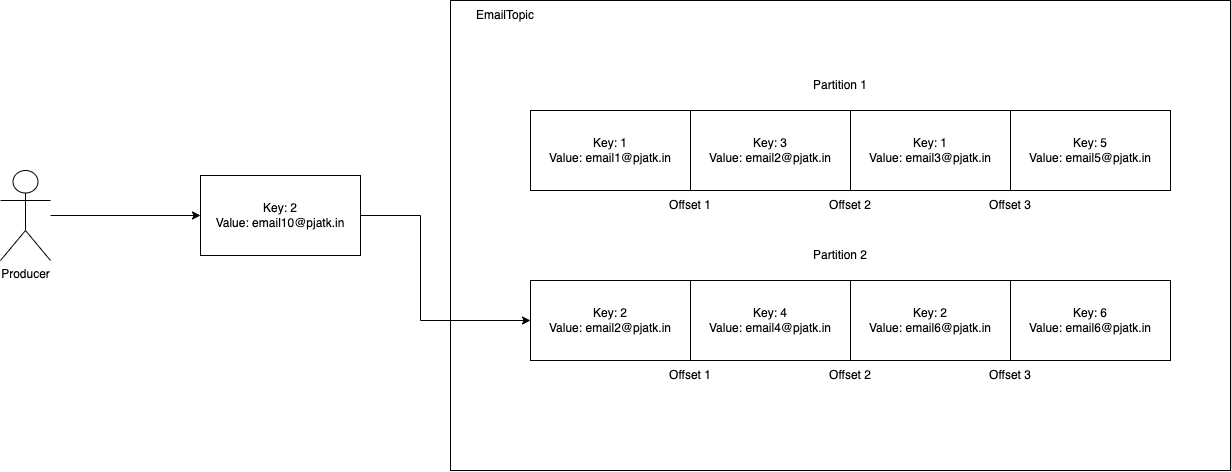
Figure 1.1. Internals of a Kafka topic without log compaction
For example, in the image above, we can see a topic with 2 partitions. Once we produce an event with key 2, it gets appended to the end of the log of partition 2.
The more messages we add, the more storage space we need for persistence. To control the amount of storage needed, we have to control when Kafka deletes the messages from the commit log. The two standard options for controlling the retention are log.retention.hours and log.retention.bytes. The first states for how many hours can a message stay in the commit log before it gets wiped. The latter controls how large the commit log can grow in bytes before Kafka removes the older messages.
However, there’s an alternative to the time-bound retention policy. This is called log compaction. Log compaction guarantees that Kafka stores at least one message for every key per a single partition. If there are two messages with the same key in the same partition, then one of them may be scheduled for deletion.
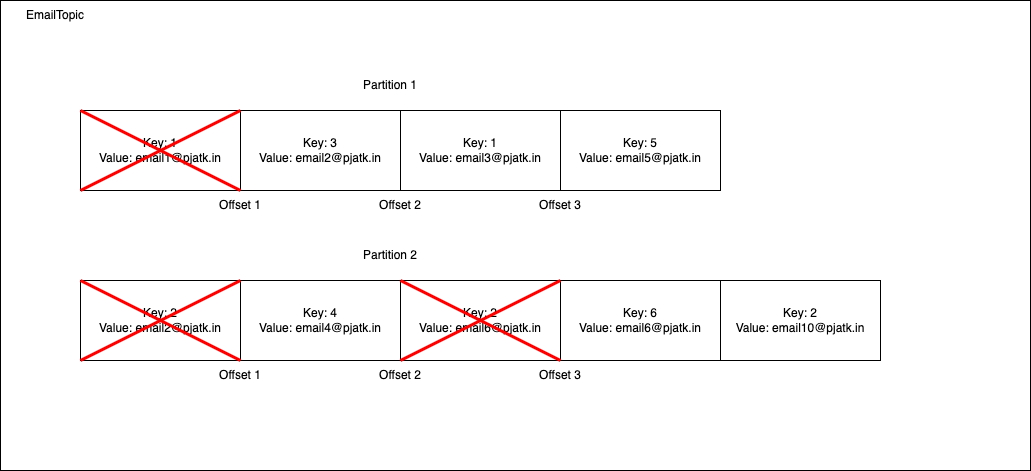
Figure 1.2. Internals of Kafka topic with log compaction
In the image above we can see that a message with key 1 in partition 1 is scheduled for deletion, the same goes for two messages with key 2 in partition 2. On the other hand, messages with keys 4 and 6 won’t be deleted.
What are the potential practical applications for log compaction? The most common use case is for recovering the state of a Kafka consumer in case of issues. For example, if a consumer needs to materialize the email changes and find out the latest email for a user with ID 2, then every time it restarts, it needs to go through all the messages to get the latest email for user 2. By storing the intermediate state to a Kafka topic with log compaction enabled, the consumer can read the latest state from the compacted topic before proceeding with consuming the latest entries from the raw topic.
On top of that, log compaction is an excellent tool for complying with GDPR-like regulations, because it allows us to clean up a log-compacted topic of unwanted data.
2. Log Compaction Internals
Even though a single partition of a topic looks like one big log file, it is not the case. Underneath, Kafka splits a single partition into multiple smaller segments stored in different files.
For example, when we go through the storage layer of a partition, we will see a similar file structure:
-rw-rw-r-- 1 root root 0 nov 1 00:02 0000.index
-rw-rw-r-- 1 root root 140 nov 1 00:02 0000.log
-rw-rw-r-- 1 root root 12 nov 1 00:02 0000.timeindex
-rw-rw-r-- 1 root root 10485760 nov 1 00:03 0006.index
-rw-rw-r-- 1 root root 70 nov 1 00:03 0006.log
-rw-rw-r-- 1 root root 56 nov 1 00:03 0006.snapshot
-rw-rw-r-- 1 root root 10485756 nov 1 00:03 0006.timeindexKafka creates quite a few files. The most important in the context of log compaction are the ones ending with the suffix .log (i.e. 0000.log and 0006.log).
These two files contain the actual messages dispatched to Kafka. 0000.log is the inactive segment. Kafka has closed that file and doesn’t append any messages to it. 0006.log, on the other hand, is the active one to which Kafka actively appends messages. The file name indicates the offset from which the messages in a particular file start.
Kafka compacts the log by building a map out of all the inactive log segments. 1

Figure 2.1. Layout of a Kafka Topic During Compaction
During the first run, the cleaner thread iterates over all the messages that are right of the firstDirty pointer. It builds a map out of all the seen messages, where the key is the message ID and the value is the offset.
During the second round of iteration, it goes through all the messages (both compacted and not yet compacted ones) and builds the second map out of the messages.
The last step of the compaction is to compare the first and the second map and to discard all the messages that have duplicates, preserving the latest message. Eventually, a cleaner thread swaps out the old segment file with a new one and progresses the firstDirty pointer.
As the log compaction works with log files of a partition, then the compaction is applied only in the context of a single partition. Hence, if a message with key 2 ends up in both partitions 1 and 2, then the messages aren’t compacted.
Log compaction doesn’t change any offsets in a partition.
3. Log Compaction in Practice
The bare minimum to get log compaction working is to set cleanup.policy for a topic to compact. For example, creating a topic with the following command enables log compaction:
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --topic email_topic --partitions 1 --config cleanup.policy=compactHowever, just enabling log compaction may not be sufficient. Kafka has many options for controlling compaction in detail.
3.1. Log Compaction Configuration Knobs
If we want to ensure the maximum time duplicate keys can be in the log before they’re compacted, we have max.compaction.lag.ms configuration option. Keys that are older than max.compaction.lag.ms will be deleted from the inactive segments.
If max.compaction.lag.ms is not specified, then the messages are removed as soon as they have existed longer than min.compaction.lag.ms and more than min.cleanable.dirty.ratio messages in the inactive part of the partition are subject to deletion.
3.2 Deleting Entries from Kafka
As it’s possible to use Kafka in a database-like setting, then it’s also possible to delete records from the topic. For deleting a record, we need to set the value of a key to null(aka tombstone).
If Kafka compacts the key marked for deletion, then the consumers will see only the null value. Once delete.retention.ms period passes (defaults to 1 day), then Kafka cleans up the tombstones themselves and the compacted keys will completely disappear from the partition.
If a consumer keeps a state about a key, then it has to read the tombstone from a topic in a period shorter than delete.retention.ms. Otherwise, the consumer will miss the tombstone and won’t remove the key from its internal state as Kafka will remove the tombstones from the log completely after the period passes.
As mentioned previously, this allows us to comply with GDPR. If a customer wants their data to be completely wiped, we have to enable log compaction and set the correct deletion retention period. After the period passes, the required data will be removed from the Kafka topic.
4. Conclusion
The article took a look at Kafka log compaction. Log compaction offers an alternative to the standard time-based message retention policy. When log compaction is enabled, then Kafka cleans up the entries with duplicate keys, keeping just the latest one.
The use cases of a log compacted topic vary from storing the intermediary state of a Kafka consumer to complying with GDPR.